

Wordle is one of the most popular word games on the internet right now. You get 6 guesses to figure out the daily 5 letter word, and each word you enter gives you clues about what letters are in the word and where they might be.
While plenty has been written about the best strategies for the game, sometimes the options available to you are hard to see. In the example in the blog post header, I probably thought for a whole minute to find my 4th guess (prowl), and it took another minute or so to find any other word that fit in with the rest of the clues. If I had been using a scrabble solver or word finder, I probably could have figured out what options were actually available to me in no time and made more reasonable guesses ("prowl" probably wasn't a good one, but neither was "frond"). But if I had used grep, I could have very quickly found exactly the words remaining.
Grep
grep is a very old Linux command line program and one of the most popular utilities to use in shell programming. At a high level, it reads lines of text and returns back any lines that match an expression you give it. For example:
grep 'hello' /usr/share/dict/wordsprints out all the words in the system dictionary file (/usr/share/dict/words) that include hello (case-sensitive). You could make it highlight the matching region of the word (as I do by default) and thus pull out the important sections from a series of lines:
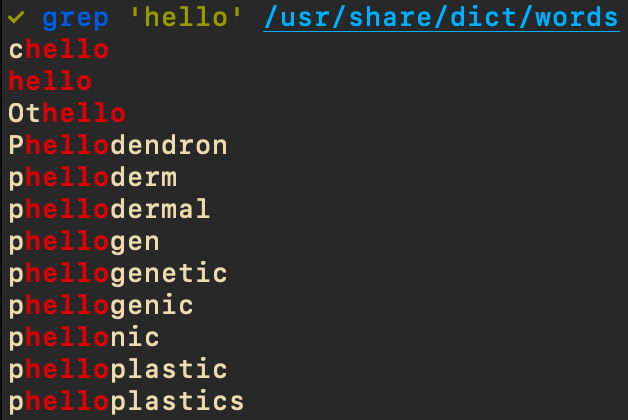
You can also build pipelines with grep to extract and transform text before sending those lines to grep. For example, to find the current active branch in a git repository OR the branch you are rebasing against (if doing an interactive rebase), I found that I could search for lines starting with a * to get the current branch name (including the leading * and a space), as git best understands it:
git branch --list --no-color | grep "^*"Grep is a very powerful tool.
Regular Expressions
The concept that powers grep is called a regular expression. These range from the extremely simple (as I'll cover today) to the utterly absurd. They allow us to match not just exact matches of text but concepts inside the text. Some examples of regular expressions I use all the time:
. = anything. To match only a period you must use a backslash: '\.'
[a-z] = any letter between a lowercase 'a' and a lowercase 'z'
[^ab] = any character BUT a lowercase 'a' or a lowercase 'b'
^st = any line starting with 'st'
rt$ = any line ending with a 'rt'
d* = zero or more occurences of the letter 'd'
f{2} = the 'f' character exactly twiceThis post unfortunately can't be a tutorial on regular expressions. There's just too much to cover and too many things to think about as you build more complicated expressions. For this post we're going to focus on building pipelines of grep commands with very simple regular expressions to help us whittle down the available words.
UNIX Pipelines
Another topic to touch on briefly are pipelines of UNIX commands to form larger programs. There isn't that much to cover really, but it can be extremely confusing if you've never worked with them before.
Most UNIX commands take a file-like object and return a stream of characters. "File-like" is important because streams of characters are included in this definition. This means I can take a file, perform an operation on it, and then pass the result of that operation to a new command that would normally only take a file. I previously showed an example of a git command I ran where the output was piped (with the pipe character |) to a grep command. When there are no more commands to absorb the stream of characters, the characters go to your terminal and you see the result.
Again, it can take a little bit to get used to, but once you "get" it UNIX pipelines are incredibly powerful and the building blocks of most of my software development work.
Building Wordle Solving Pipelines
Now we get to the fun part: actually trying out grep as a Wordle helper.
Let's start by finding all the 5 letter words. Do I know what dictionary list Wordle uses? No. But so far the dictionary in /usr/share/dict/words has had all the words I've seen the game use. Maybe that's a bad assumption, but right now I'll roll with it.
First step
We'll start with the first part of the pipeline: limiting the output from the dictionary file. We have 2 constraints to account for to match the (assumed) rules of the game:
- Every character in the word must be a lowercase alpha character (A through Z, no punctuation!).
- There must be exactly 5 of these characters.
With that we can build the initial part of our pipeline:
grep -E '^[a-z]{5}$' /usr/share/dict/wordsUnfortunately grep doesn't have support for some operations straight out of the box, so we have to use the -E flag to use extended regular expressions.
My dictionary file has 8497 words matching this pattern. Not great.
Second step, first guess
You'll have to guess your first word yourself. Sorry. I'll guess the word "raise" for today's Wordle (solution as the title image).

What did we learn?
- There is at least one R in the word, but it's not the first letter.
- There are none of: A, I, S, or E.
The first bullet gets added to our pipeline as two separate greps: one to look for any R and the other to remove those starting with an R:
grep -E '^[a-z]{5}$' /usr/share/dict/words \
| grep 'r' \
| grep '^[^r]'The second bullet requires the -v flag, which inverses the matching power of grep. So we can look for lines not matching any of A, I, S, and E:
grep -E '^[a-z]{5}$' /usr/share/dict/words \
| grep 'r' \
| grep '^[^r]' \
| grep -Ev '[aise]'My dictionary returns back 271 words once these restrictions have been applied. Still not enough to do much.
Third step, second guess
Come up with a second guess. I see there are a lot of words starting with B and C left in the list, so maybe I want to guess something with those letters. I don't like guessing words with double letters this early, so maybe I'll do something "crout", which is both apparently a word and uses each of the remaining vowels.

Pretty good! What did we learn this time:
- There is an R is the second position.
- There is an O in the third position.
- There is no C, U, or T.
We could modify the previously pipeline, or we could keep adding on processing. Adding on processing is rarely slow enough to matter and will make you pipelines easier to understand:
grep -E '^[a-z]{5}$' /usr/share/dict/words \
| grep 'r' \
| grep '^[^r]' \
| grep -v '[aise]' \
| grep '^.ro' \
| grep -v '[cut]'This gets us down to 33 words! Wow! That's small enough we can start thinking about patterns.
Fourth step, third guess
I see many words left starting with a B, but they mostly have double O's in the middle and that's still not appealing. I see many N's and W's though, so I think "brown" is a good guess that should eliminate many options:

We now apply our learnings to our pipeline:
grep -E '^[a-z]{5}$' /usr/share/dict/words \
| grep 'r' \
| grep '^[^r]' \
| grep -v '[aise]' \
| grep '^.ro' \
| grep -v '[cut]' \
| grep -v '[bwn]'Wow! Only 13 words left!
Fifth step, fourth guess
We're now down to very few words and it's worth thinking about strategy. Half the remaining words have a double O in the middle. 5 have a G and 5 have a D, but none have both a D and a G. Some of the remaining words feel like very unlikely Wordle words (apparently "drogh" means evil or wicked), so I'll choose to avoid the F words:
grep -E '^[a-z]{5}$' /usr/share/dict/words \
| grep 'r' \
| grep '^[^r]' \
| grep -v '[aise]' \
| grep '^.ro' \
| grep -v '[cut]' \
| grep -v '[bwn]' \
| grep -v 'f'Now 5 words have a D, 4 have a double O, and 3 have a P. That seems like the best combination of options, so I'll guess "droop":

This was actually very good! We eliminated all the double O words, we know there's a P in there, and the most common letter left (D) has been eliminated!
Now we undo the operation on the F and apply new operations to our pipeline:
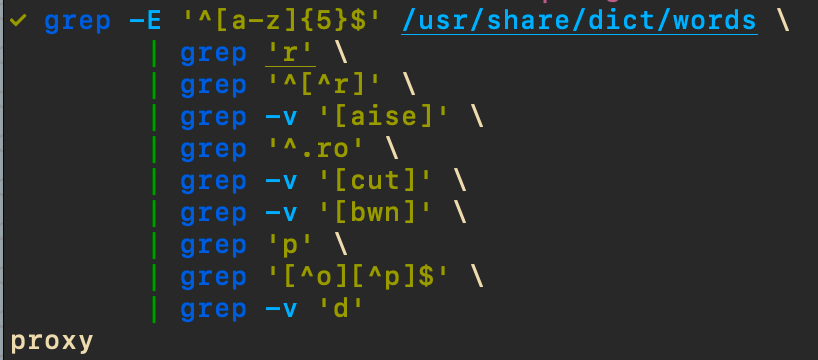
grep -E '^[a-z]{5}$' /usr/share/dict/words \
| grep 'r' \
| grep '^[^r]' \
| grep -v '[aise]' \
| grep '^.ro' \
| grep -v '[cut]' \
| grep -v '[bwn]' \
| grep 'p' \
| grep '[^o][^p]$' \
| grep -v 'd'Sixth step, winning
There's only one word left!

Summary
While it took the same number of guesses to use grep as it did my regular attempt, we were able to apply better filtering to our results along the way and make better and better decisions. The decisions were so good that there were literally no other options at the end and we were guaranteed a victory.
But maybe more importantly than the word game, you now have a better understanding of how to use grep and some simple regular expressions. These will be valuable in more ways than you can imagine, from quickly finding the file that has the thing you want to efficiently filtering out garbage from large blobs of output. Mastering and aggressively grep might be the greatest superpower you can have on the command line.
greps.